Tot kort bestond de belasting op laagspanningsnetten vooral uit gloeilampen, wasmachines, drogers en koelkasten. Tegenwoordig is de basisbelasting veranderd door ledverlichting, vaatwasmachines, computers en is er een opkomst te zien in apparaten zoals warmtepompen, zonnepanelen en opladers van elektrische auto's. De onzekerheid van de belasting van aansluitingen begint toe te nemen, door deze apparaten. Daarom is de oude Strand-Axelsson-methode, die werkt met één normaalverdeling, toe aan verandering. Met behulp van GM-types kunnen de belastingen nauwkeuriger worden bepaald.
Gaia heeft standaard al een aantal GM-types die gebruikt kunnen worden, maar er is ook de mogelijkheid om de types zelf aan te maken. De GM-belastingtypegenerator is de tool die daarvoor gebruikt kan worden. De GM-types vormen de kansverdelingen die als invoer dienen voor de netberekeningen. Deze GM-types zijn Gaussian Mixture modellen die bestaan uit vier normaalverdelingen.
Er kunnen GM-types gemaakt worden van apparaten en van basisbelastingen. Basisbelastingen zijn de verzameling van apparaten op één aansluiting. Met behulp van disaggregratie kunnen apparaten die relatief veel elektriciteit gebruiken/opwekken worden weggefilterd, om een basisbelasting te creëren waaraan de meeste aansluitingen voldoen. De gebruiker kan zelf GM-types van specifieke apparaten aanmaken en toevoegen aan de aansluitingen. Deze apparaten kunnen worden gestapeld op de basisbelasting, om zo het volledige gebruik van aansluitingen te bepalen.
Start de typegenerator met Extra | Definities | GM-typegenerator.
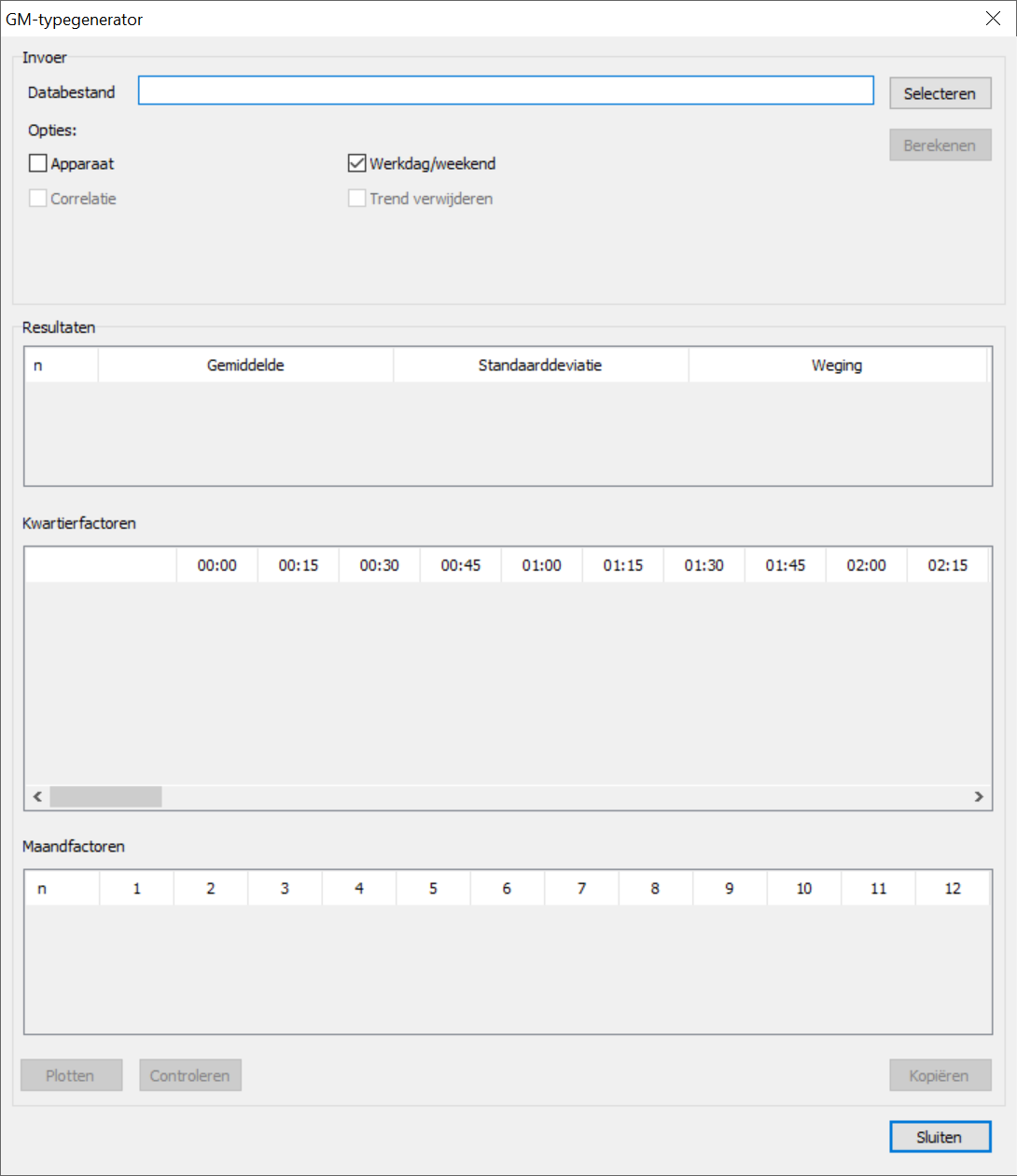
GM-type aanmaken
Druk Selecteren om het databestand te selecteren waarvan het GM-type gemaakt moet worden.
Voor het aanmaken van een GM-type is een databestand nodig. De GM-belastingtypegenerator ondersteunt tekst-databestanden. In dit tekstbestand wordt per regel eerst het tijdstip aangegeven, waarna de gemeten vermogens volgen. De waarden worden gescheiden met een tab of een puntkomma. Het decimaalteken van de getallen kan een komma of een punt zijn. Het is belangrijk dat het databestand volledig is. Een complete dataset bevat slimme meterdata van elektrische vermogens over elk kwartier van het hele jaar, waarbij ook het liefst zoveel mogelijk gemeten vermogens per tijdstip. Elke aparte kolom bevat de gegevens over één specifieke meter. De typegenerator ondersteunt alleen positieve vermogens die uitgedrukt worden in kilowatt. Dit is een voorbeeld van de indeling van het tekstbestand:

Per regel geldt de volgende notering:
D-M-YYYY HH:MM:SS vermogen_meter_1 vermogen_meter_2 vermogen_meter_3 ………
De kwaliteit van de GM-types is sterk afhankelijk van de kwaliteit van het databestand. Een paar voorbeelden van handelingen die een negatieve invloed uitoefenen op de kwaliteit van de GM-types zijn: het onjuist categoriseren van de gegevens, erg weinig gemeten vermogens per tijdstip gebruiken en verschillende eenheden hanteren.
Bij het groepje Invoer zijn verschillende opties te zien. Elk van deze opties heeft invloed op de rekenmethode. Hieronder worden de opties uitgelegd:
Apparaat
Als de optie Apparaat is aangevinkt dan wordt de uitkomst van de berekening uitgedrukt in een percentage. De gebruiker kan per apparaat zelf het vermogen aangeven. Als deze optie niet is aangevinkt dan wordt de basisbelasting berekend. GM-types hanteren voor apparaten één normaalverdeling in plaats van vier bij de basisbelasting.
Werkdag/weekend
Als de optie Werkdag/weekend is aangevinkt dan worden de gegevens uit het databestand opgesplitst in werkdagen en weekenddagen. Vervolgens worden parameters opgesteld van twee aparte kansverdelingen om onderscheid te maken tussen werkdaggebruik en weekendgebruik.
Trend verwijderen (alleen voor apparaten)
Als de optie Trend verwijderen is aangevinkt dan worden terugkerende patronen uit de data verwijderd, om zo een reëel gemiddelde te bepalen. Met behulp van de optie Trend verwijderen kan er onderscheid worden gemaakt tussen de opwekking/belasting in bepaalde periodes van het jaar. Normaal staat het gemiddelde van de normaalverdeling vast, alleen de hoogte van de verdeling varieert. Wanneer Trend verwijderen is gekozen dan kan het gemiddelde van normaalverdeling ook veranderen. Deze optie wordt gebruikt bijvoorbeeld bij zonnepanelen.
Correlatie (alleen voor apparaten)
Correlatie wordt op dit moment niet berekend door de GM-belastingtypegenerator. Correlatie wordt toegepast op apparaten die een vergelijkbaar patroon in elektriciteitsgebruik vertonen. De correlatie van het GM-type kan de gebruiker (vooralsnog) zelf aangeven in het typenbestand. Bij zonnepanelen wordt een correlatie van één aangeraden.
Als het databestand is ingevoerd en de opties geselecteerd zijn, kunt u klikken op de knop Berekenen. Het berekenen van GM-types kan lang duren afhankelijk van de grootte van de dataset.
GM-type aflezen en opslaan
Nadat het GM-type is berekend, kunt u de gegevens aflezen en opslaan.
Nadat de berekening is uitgevoerd, kunt u de tijdsfactoren, maandfactoren, gemiddeldes en standaarddeviaties aflezen. Deze gegevens vormen samen de parameters van de normaalverdelingen waaruit de GM-types zijn opgebouwd. Ook is er de mogelijkheid om het GM-type visueel weer te geven door op de knop Plotten te klikken. Het volgende venster verschijnt:
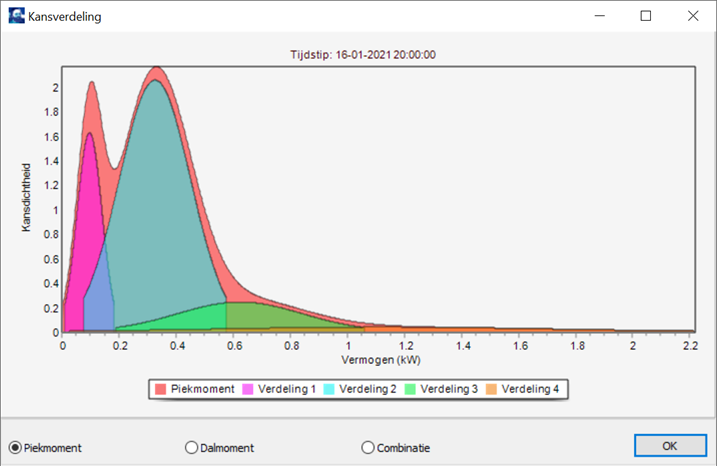
Het GM-type kan worden weergegeven tijdens de belastingpiek, opwekkingspiek en er kan een combinatie van beide worden weergegeven met de keuze Combinatie. De plotfunctionaliteit geeft een vereenvoudigde afbeelding weer van het GM-type, om inzicht te geven in de vorm van het GM-type.
Nadat het GM-type is berekend komt er een tekstveld tevoorschijn. Hier kunt u de naam van het GM-type invullen. Vervolgens kunt u het GM-type opslaan door op de knop Kopiëren te drukken. De gegevens worden dan gekopieerd naar het klembord van de computer. U kunt zelf het gekopieerde GM-type in het typenbestand (Types.xlsx) plakken.
GM-type controleren
De GM-types kunnen worden gecontroleerd op correctheid. Dit gebeurt door de GM-types te vergeleken met het databestand. Hierbij worden samples die gegenereerd zijn uit het GM-type en de gegevens uit het databestand gebruikt. Het kan voorkomen dat het uitgerekende GM-type afwijkt van de dataset. Dit ligt meestal aan de kwaliteit van het databestand zelf, als er bijvoorbeeld te weinig metingen per tijdstip zijn aangegeven. Door op de knop Controleren te klikken verschijnt de volgende venster:
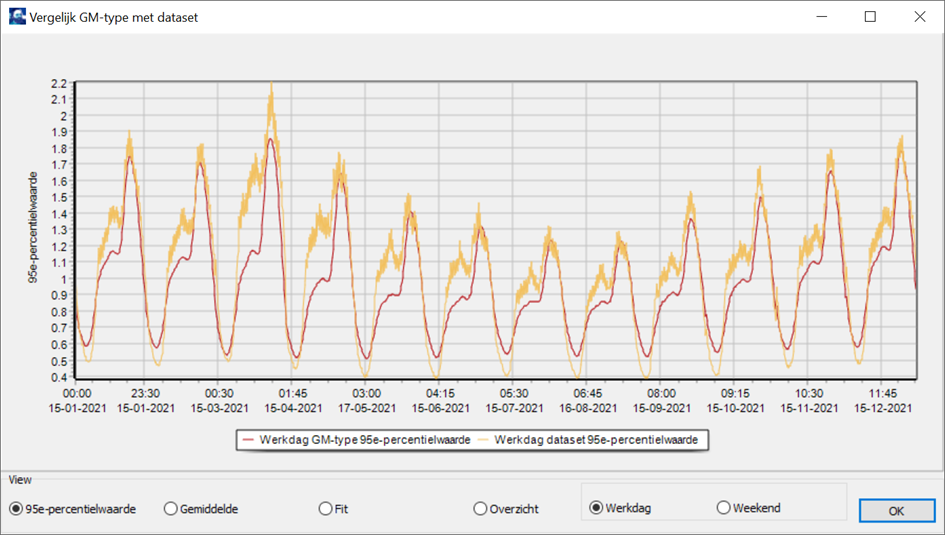
Als de optie Werkdag of Weekend is geselecteerd bij het berekenen, dan worden de gegevens van werkdagen en weekenden apart weergegeven.
Als 95e-percentielwaarde is gekozen, dan kunnen de 95e-percentielwaardes door het jaar afgelezen worden. Deze worden toegepast bij de netberekeningen. Het is dan ook belangrijk dat de waardes van de dataset goed overeenkomen met de waardes van de samples uit het GM-type.
Als Gemiddelde is gekozen, dan kunnen de gemiddeldes door het jaar afgelezen worden. Hoe dichter deze bij elkaar liggen hoe beter de benadering is.
Als Fit is gekozen, dan kunnen de fit scores door het jaar afgelezen worden. De fit geeft de overlapping aan tussen de dataset en het GM-type. De fit kan maximaal één zijn. Hoe hoger de fit, hoe beter de overlapping. De fit is de mate waarin de vorm van de verdeling met het databestand overeenkomt. Dat de fit niet precies gelijk is aan één is te verwachten. De samples van de GM-types worden namelijk op een stochastische wijze gegenereerd en de kans dat de getallenreeksen precies overeenkomen met elkaar is dus vrij klein.
Als Overzicht is gekozen, dan kunnen de 95e-percentielwaarde, het gemiddelde en de fit worden afgelezen tijdens de belastingspiek en de opwekkingspiek. De belangrijkste maatstaf is de 95e-percentielwaarde bij de belastingspiek en opwekkingspiek. Het is van belang dat de 95e-percentielwaarden van het GM-type en het databestand dichtbij elkaar liggen. Deze getallen dienen namelijk als invoer voor de netberekeningen. De fit en het gemiddelde zijn voor de netberekeningen minder relevant en zeggen vooral iets over de nauwkeurigheid van de totale benadering.